



文章目录
- 前言
- 体系结构
- SQL语句的执行流程
- 1、连接MySQL
- 2、查询缓存
- 3、解析SQL语句
- 4、优化SQL语句
- 5、执行SQL语句
- 总结
前言
如果你在使用MySQL时只会写sql语句的,那么你应该看一下《MySQL优化的底层逻辑》。如果你只了解到sql是如何优化的,那么你应该通过本文了解一下Mysql的体系结构以及sql语句的执行流程。
体系结构
先来看下MySQL的体系结构,下图是在MySQL官方网站上扒下来的,所以有很高的权威性和准确性。
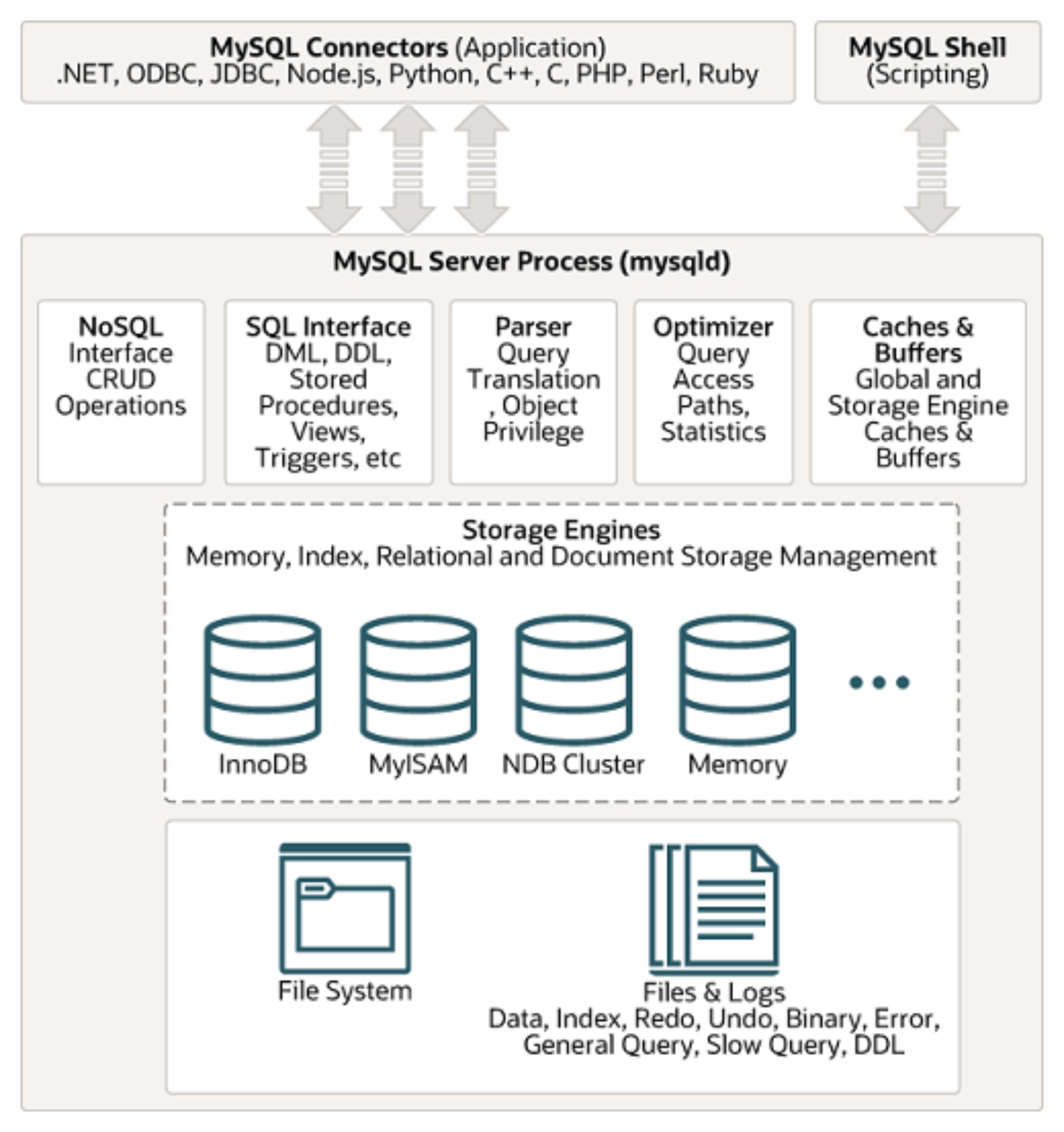
通过这张图,我们可以直观的看到MySQL的内部结构,包括连接器、缓存、解析器、优化器、存储引擎以及支持DDL、DML、存储过程、视图等功能的SQL接口。接下来,通过一条sql语句的执行来深入了解MySQL各个组件功能以及其作用。
SQL语句的执行流程
1、连接MySQL
通常我们会编写sql语句通过某个客户端来执行并且接受执行结果,比如命令行、JDBC、navicat。但是在执行前肯定需要先和MySQL服务成功建立连接,这个就是「连接器」的工作。
这里通过命令行的方式MySQL服务建立连接,命令如下:
mysql -h127.0.0.1 -uroot -p
命令连接的是本地的MySQL服务,在输入密码后,连接器会验证用户和密码,如果验证失败会给客户端响应拒绝访问的信息。

验证成功后,连接器会与该客户端成功建立连接并且读取该用户的权限,用户之后的操作都会基于权限进行控制。
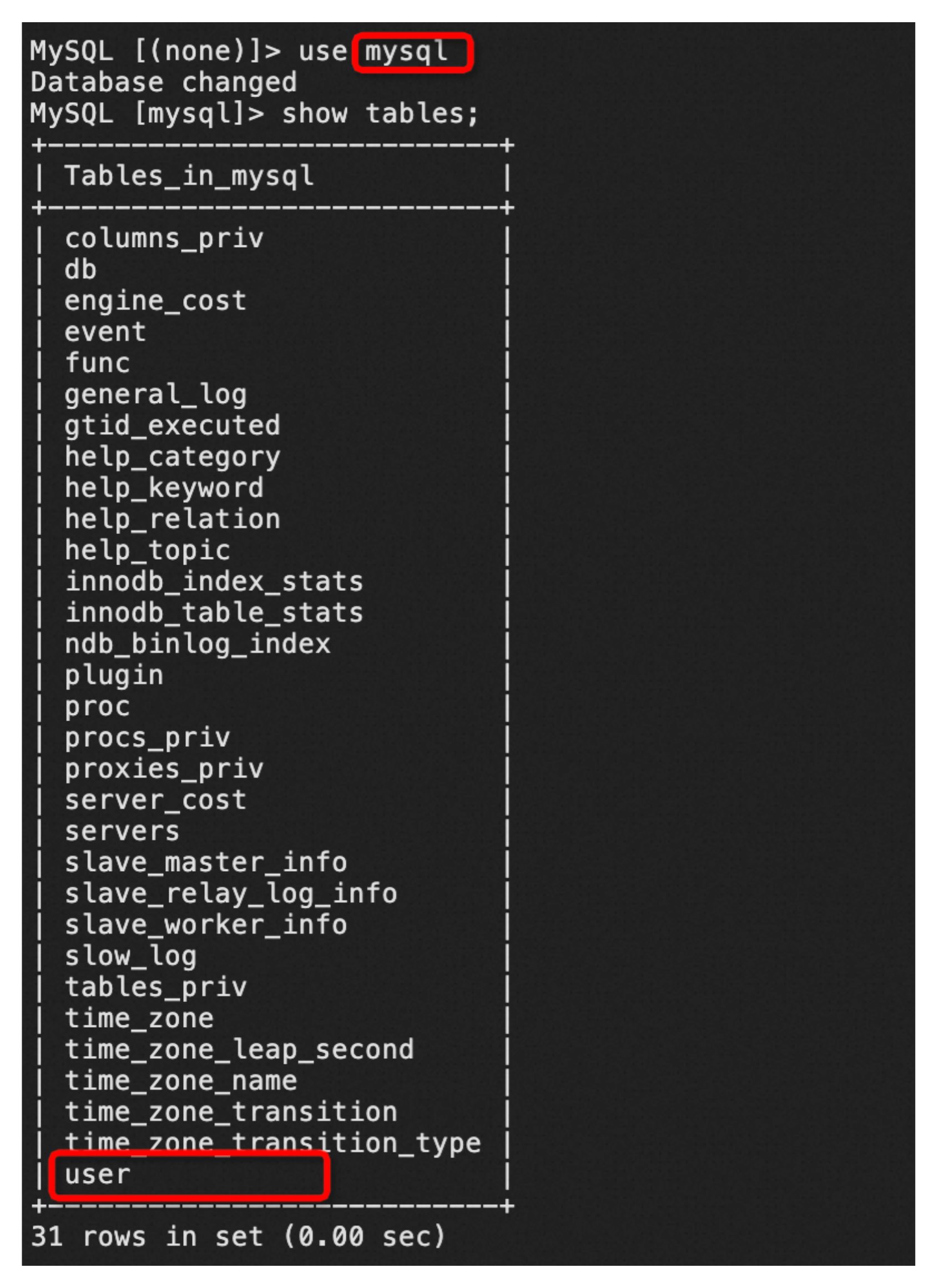
那么用户名和密码以及权限在哪存储呢?
在MySQL中,除了开发人员创建的业务库,还有支撑自己运行的系统库,包括mysql、sys、perfermance_schema、information_schema,用户信息就存储在mysql这个库。
当然,MySQL的连接数也是有限制的,这个可以通过max_connections参数控制。
MySQL [mysql]> show variables like 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 1215 | +-----------------+-------+
也可以通过 show processlist 查看当前连接的客户端。
MySQL [mysql]> show processlist; +------+------+-----------------+-------+---------+------+----------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +------+------+-----------------+-------+---------+------+----------+------------------+ | 1156 | root | 127.0.0.1:61223 | mysql | Query | 0 | starting | show processlist | +------+------+-----------------+-------+---------+------+----------+------------------+
2、查询缓存
当成功建立连接后,客户端就可以向MySQL服务发送sql语句了,「SQL接口」就像我们写的Controller一样会接收到sql语句,如果是 select 语句,将会去「缓存」中检索结果响应给客户端。
有些博客的说法是在解析后才查询缓存,这种说法是不严谨的,这里抛出官方的说明“如果收到相同的语句,服务器将从查询缓存中检索结果,而不是解析并再次执行该语句”
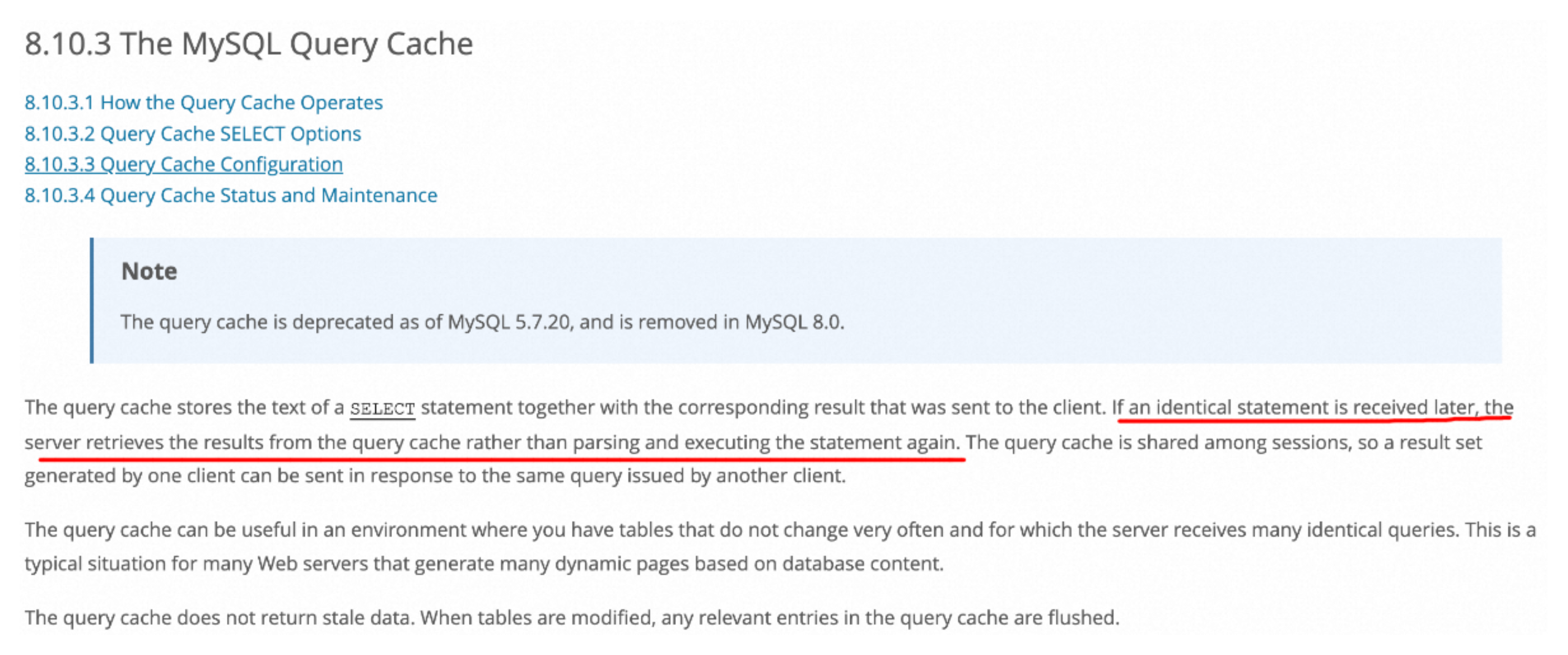
同时在该说明中可以看到“从MySQL 5.7.20开始,查询缓存已被弃用,并在MySQL 8.0中被删除。”这个注释。按照官方的说法是“缓存只适用于表数据不会经常变动的场景,如果表数据经常更新(很明显大多是这个场景),缓存命中率低下,加上频繁的维护缓存,有时候造成的问题比解决的问题还要多,缓存的功能就显得比较鸡肋了。”
3、解析SQL语句
在经过缓存后,就由「解析器」开始工作了,解析器的目的是检查sql语句是否正确以及将sql语句解析成MySQL能够理解的结构,也就是sql语法树。
像 select1 id from table1 这条sql语句就会在解析时报错,因为没有识别到 select 这个关键字(对列名、表名的检查和验证是在预处理阶段)。

而像 select id from table1 这条sql语句会被解析成下图:
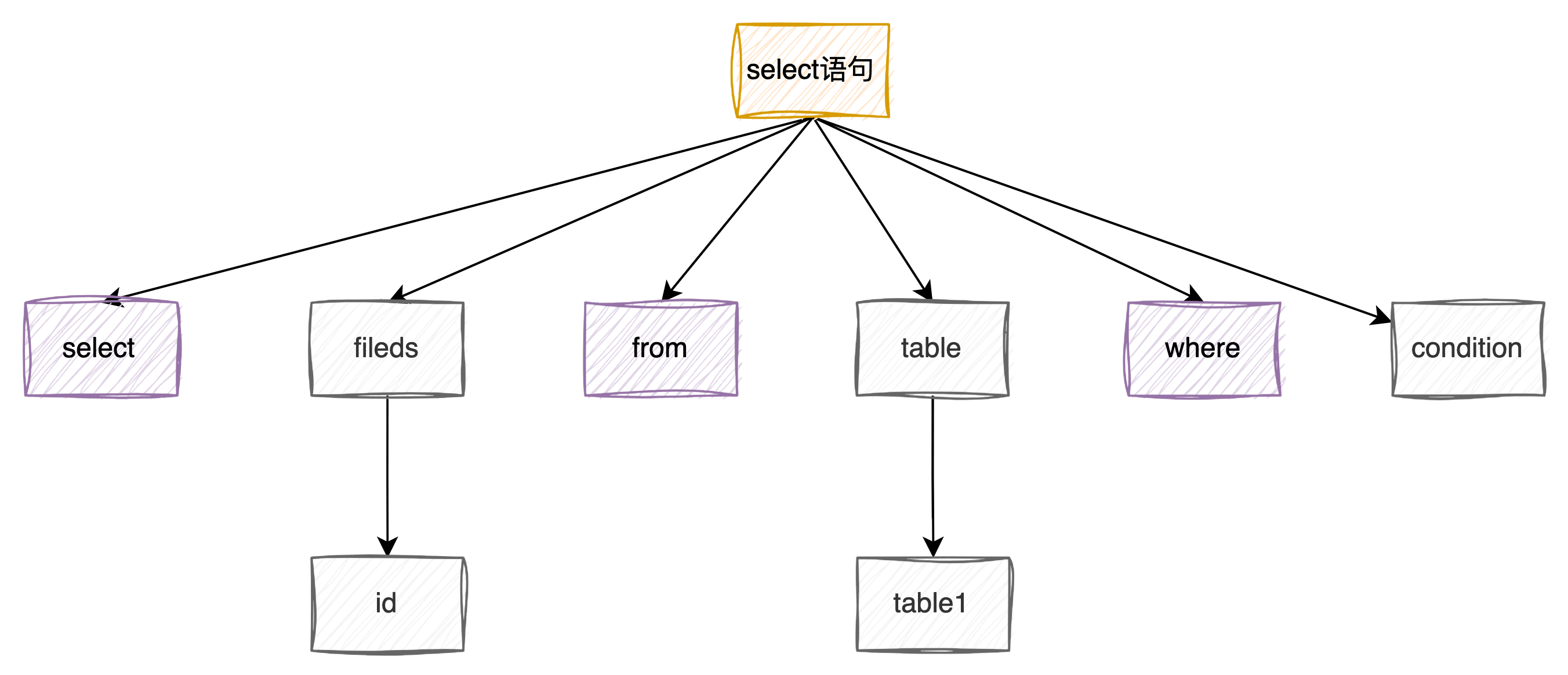
如果想了解具体的解析过程可以参考这篇博客
4、优化SQL语句
通过解析器生成sql语法树后就到了「优化器」阶段了,sql如何执行、使不使用索引、使用哪个索引都是在这个阶段处理,《MySQL优化的底层逻辑》中有写到,这里不过多赘述。
5、执行SQL语句
经过「优化器」后最终生成一个最优的执行计划交给「执行器」来执行,执行器通过调用「存储引擎」的接口来获取数据,这里先不展开执行器与存储引擎的交互,后面的文章会详细阐述一下。
总结
至此,一条查询语句的执行流程已经非常清晰了,同时也认识了MySQL的整个体系结构以及各组件的作用。最后用一张图来收尾本文的核心内容并做总结。
一条查询SQL语句的执行流程:
- 客户端通过连接器连接MySQL服务。
- 连接成功后向SQL接口发送SQL语句请求。
- SQL接口接收到SQL查询语句会先去缓存查询,如果命中返回给客户端,否则交给解析器。
- 解析器在拿到SQL语句后会判断语法是否正确,正确会生成sql语法树交给优化器,否则报错给客户端。
- 优化器会根据sql语法树生成一个最优的执行计划交给执行器执行。
- 执行器拿到执行计划调用存储引擎来获取数据响应给客户端。
- 完成!!!
上一篇:介绍几种Go语言开发的IDE

- 关注我们
- 扫描二维码
- 获取更多信息
- 精彩一手掌握







