



- SpringCloud整合nacos配置中心bootstrap.yml
- 基于python+mysql的可视化图书管理系统(文末附源码)
- mysql报错解决方式:1449 - The user specifi
- Springboot-Redisson - 1.简介和配置
- Springboot工资管理系统 计算机毕设源码32779
- 建立数据库连接时出现错误:原因与解决方案
- 如何把本地flask项目(框架)上传到服务器(Linux),并后台持续
- @Transctional事务传播机制(Propagation)
- SQL server数据库期末大作业
- zookeeper安装和启动
- 企业级SQL开发:如何审核发布到生产环境的SQL性能
- MySQL——存储过程和函数从零基础到入门必学教程(涵盖基础实战)
- Java spring 注解 @PostConstruct 实战讲解
- <SpringBoot笔记>SpringBoot版本降级
- SpringCloud Alibaba(一)微服务简介+Nacos的安
- 鲜花商城系统设计与实现(Java+Web+MySQL)
- nvm管理node 无法正常切换node版本问题
- 如何在Spring Boot中禁用Actuator端点安全性?
- 【⑦MySQL】· 一文了解四大子查询
- (附源码)springboot学生宿舍管理系统毕业设计161542
- PHP基础语法(上)
- 1. GO 之基础命令
- 【SpringBoot】| Spring Boot 概述和入门程序剖析
- acme.sh自动配置免费SSL泛域名证书并续期(Aliyun + D
- 【MySQL】表的基本查询
- linux系统部署springboot项目,过程详细!
- SpringBoot对接小程序微信支付
- SQL开窗函数之前后函数(LEAD、LAG)
- 数据库实战:基于Tkinter+MySQL的学生成绩管理系统
- 学生信息管理系统MySql课程设计
 12-2523基于flask的web应用开发——访问漂亮的html页面以及页面跳转
12-2523基于flask的web应用开发——访问漂亮的html页面以及页面跳转目录0. 前言1. html基本知识2. 编写html文本3. 在Flask中设置访问html4. 实现点击跳转0. 前言 本节学习如何在flask应用程序下让用户访问你提前制作好的html页面 操作系统:Windows10 专业版...
 12-2523Maven:指定 JDK 版本
12-2523Maven:指定 JDK 版本指定 JDK 版本 第一种方式 settings.xml 配置 jdk-1.8true1.81.81.81.8 第二种方式 在当前 Maven 工程 pom.xml 中配置...
 12-2523爬虫beautifulsoup库常用函数的使用
12-2523爬虫beautifulsoup库常用函数的使用beautufulsoup作为爬虫网页的解析库,凭借它的简单易懂得到了广泛的使用。下面以beautiful常用函数为例。 soup.title 打印标题,包括标签和文本。soup.title.name...
 12-2523<SpringBoot笔记>SpringBoot版本降级
12-2523<SpringBoot笔记>SpringBoot版本降级设计软件及版本:IDEA 2021.1.3 x64、JDK11、SpringBoot2.7.5 🔗JDK11下载链接 场景:使用IDEA时发现SpringBoot与JDK版本不兼容。在SpringBoot3.0之后,...
 12-2523MyBatis:动态 SQL 标签
12-2523MyBatis:动态 SQL 标签MyBatis动态 SQL 标签if 标签where 标签trim 标签choose 、when 、otherwise 标签foreach 标签附动态 SQL 标签 MyBatis 动态 SQL 标签,是一组预定义的标签,用于构...
 12-2123理解pom.xml中的parent标签
12-2123理解pom.xml中的parent标签✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉🍎个人主页:Leo的博客💞当前专栏: 循序渐进学Spri...
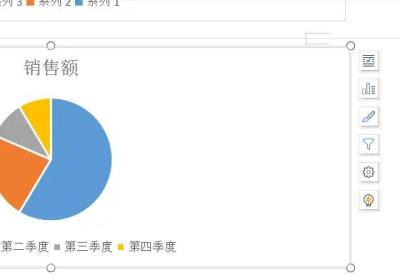 12-1423SpringBoot + Poi-tl操作word,快速生成报表
12-1423SpringBoot + Poi-tl操作word,快速生成报表前段时间做了一个需求:需要快速生成一份数据报告,里面包含了文字、图片和数据报表,同时生成的图形数据也可以随意修改。之前想着使用Apache POI来进行实现,在翻阅一些资料后,发现poi-tl更适合我们的业务,也更容易上手,于是对其进行了研...
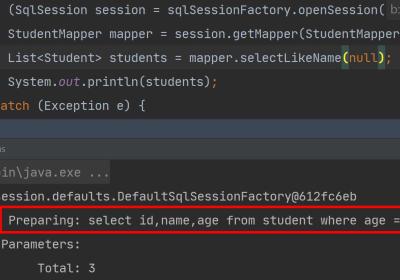 12-1423Java
12-1423Java一、动态SQL 1.概述 动态SQL: 是 MyBatis 的强大特性之一,解决拼接动态SQL时候的难题,提高开发效率分类 ifchoose(when,otherwise)trim(where,set)foreach2.if做 wh...
- 12-1423头歌 · NoSQL系列课程 · Neo4JMongoDB 实验
科研部建设中,覆盖歌云端实验平台对于Neoj4、MongoDB 的实验项目目录 目录 编辑 Neo4j 实验一、二 MonGoDB实验三、四 实验五六、redis Neo4j 实验一、二 NoSQL专项1. 第1关:...
- 12-1423【网络安全带你练爬虫-100练】第2练:爬取指定位置数据
目录 一、思路 二、工具 三、代码处理 第一部分:发起请求+接收响应(不过多讲) 第二部分:解析HTML页面+提取数据 第三部分:处理数据 一、思路 分解步骤,化繁为简 爬虫分为五步走:发起HTTP请求:爬虫使用HTTP协议向目标网...
- 12-1323intellij idea里的springboot写html页面报错A ‘viewport‘ met
在html代码的head标签里加...
- 12-1323网页设计制作教程html(从入门到精通)
问本文主要涉及哪些话题?ll的基础知识、标签的使用、样式的设置、表单的制作等内容。guage)是一种标记语言,用于创建网页。HTML文件包含一系列标签,这些标签定义了网页的结构和内容。HTML文件可以由文本编辑器编写,也可以使用专业的网页编...
- 12-1323学习HTML网页制作必备的源码教程
HTML是网页制作的基础,掌握HTML源码是学习网页制作的必备技能。本文将为大家介绍,帮助大家快速入门。1.HTML基础语法HTML是超文本标记语言,它使用标签来描述网页的内容和结构。学习HTML的步是了解HTML基础语法,包括标签、属性、...
- 12-1323HTML网页制作代码大全(适合初学者快速入门)
随着互联网的普及,网页制作成为了一项非常重要的技能。而HTML作为网页制作的基础语言,更是每个想要从事网页制作的人必须学习的语言。本文为初学者提供了HTML网页制作代码大全,希望能够帮助大家快速入门。1.文字标签1.1标题标签~用于定义标题...
- 12-1323Python爬虫(1)一次性搞定Selenium(新版)8种find
selenium中有8种不错的元素定位方式,每个方式和应用场景都不一样,需要根据自己的使用情况来进行修改 8种find_element元素定位方式1.id定位2.CSS定位3.XPATH定位4.name定位5.class_name定...
 12-1323SpringBoot结合MyBatis 【超详细】
12-1323SpringBoot结合MyBatis 【超详细】1、SpringBoot+老杜MyBatis 一、简单回顾一下MyBatis 二、快速入门 三、简易插入删除更改 四、查询 ①、按其中一个字段查询 ②、按所有字段进行查询 五、详解MyBatis核心配置(复习) 六、结合Web及Spri...
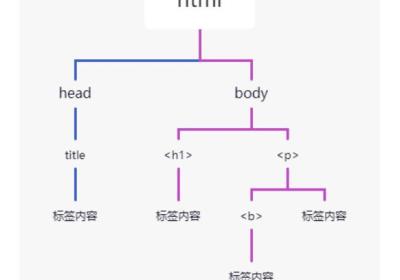 12-1323Python爬虫技术系列-02HTML解析-BS4
12-1323Python爬虫技术系列-02HTML解析-BS4Python爬虫技术系列-02HTML解析-BS42 Beautiful Soup解析2.1 Beautiful Soup概述2.1.1 Beautiful Soup安装2.1.2 Beautiful Soup4库内置对象 2.2...
- 12-1223标签,并在标签中编写CSS代码。例如
body{d-colorffffff;colorff0000;你的网页内容...
- 12-1223抖音运营秘籍如何让你的视频走红?
抖音是当下非常流行的社交媒体平台,对于许多人来说,抖音不仅仅是一个娱乐平台,更是一种赚钱的方式。但是,要想在抖音上获得成功并不容易,需要一些技巧和秘籍。本文将为大家分享抖音运营的秘籍,帮助你的视频走红。1.选择热门话题抖音上的视频类型就是与...
- 12-1123Python----网络爬虫
目录 1.Robots排除协议 2.request库的使用 3.beautifulsoup4库的使用Python网络爬虫应用一般分为两部: (1)通过网络连接获取网页内容 (2)对获得的网页内容进行处理 - 这两个步骤分别使用不同的函数...

- 关注我们
- 扫描二维码
- 获取更多信息
- 精彩一手掌握







